介绍Raft状态机实现线性一致性读的几种方法。
什么是线性一致性(Linearizability)?
线性一致性并非限定在分布式语境下面,在单机单核环境下可以简单地理解为“寄存器”特性。寄存器中的变量可以被原子地被修改,且后续对该变量的读取会返回当次修改的值,直到其被再此修改,简单来说是保证读到最近更新的值。
拓展到分布式语境下,对于系统中的状态或变量发起修改不再是瞬间完成的,从调用开始到调用返回会有一段时间开销。如何判断一个分布式系统是具备线性一致性?首先我们约定好线性一致性条件下请求之间的相互关系:
- 对于调用时间有交叠的
并发请求,生效的顺序可以任意确定,比如分别有并发的读写请求,那么读请求可以返回新值,也可以返回旧值。 - 对于调用时间有
偏序的请求,比如请求B开始在请求A结束之后,那么请求B的结果不能违背请求A已确定的结果。
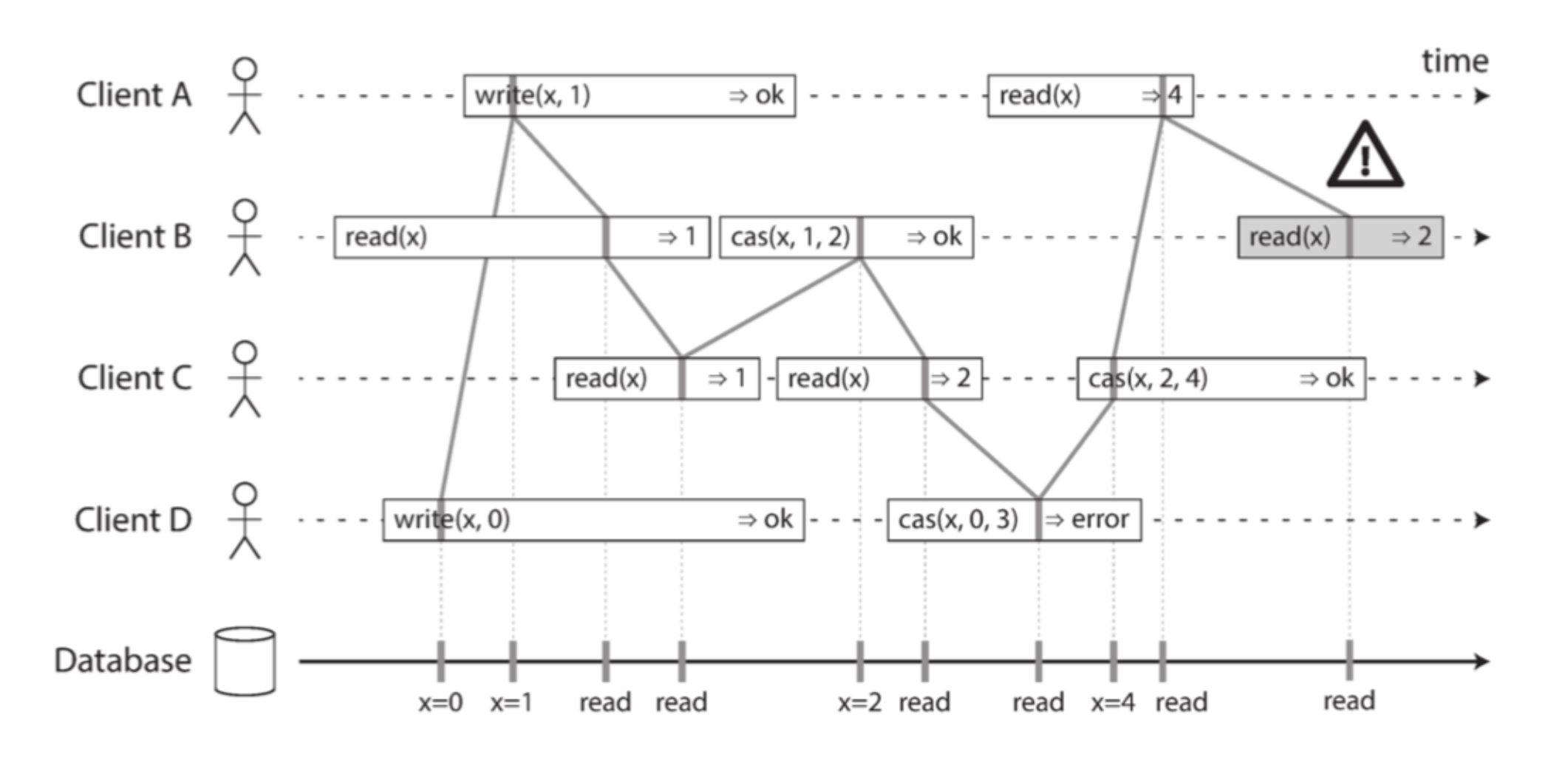
然后按照上述给定的请求关系,结合实际调用结果来判断有否出现结果与约定相违背的情况,没有的话整个系统就符合线性一致性。如上图所示,我们可以认为线性一致性系统仿佛有一条隐藏的全局时间轴,每个请求调用的过程中都有一个生效瞬间(如“|”竖线所示)、在全局时间轴上有具体的时间戳,如果将调用生效瞬间按顺序连接起来,所有连线都会呈现从左到右、顺序发生的关系。看图中最后3个请求,cas(x,2,4)与两个read(x)分别都是并发关系,然而两个read(x)是有偏序的,说明后一个read(x)应该能读到前一个read(x)的结果。cas(x,2,4)虽然是与最后的read(x)是并发关系,但由于它的修改结果是成功的,说明其必须发生在前一个read(x)之前,所以到最后我们没法从最后3个请求中发现合理的调用顺序,所以系统不是线性一致性的。
说了那么多,为什么需要线性一致性呢?我个人的理解是可以简化编程模型。写代码已经很难了,如果能够依赖更简洁明白的数据结构、逻辑约定,那么至少可以保证不容易出错。
Raft线性一致性读
分布式环境下,raft leader一般能保持最新的数据,因此读请求从leader发起是必须的,但直接从leader状态机读并不能完全确保系统的线性一致性。比如发生网络分区,旧leader处于少数派分区中,且刚好在heartbeat时间内没能发现leadership丢失,如果此时直接从旧leader的状态机读,则很可能返回stale的结果。假设新leader已被选举出来且提交了新的记录,此时有两个客户端分别从新旧leader读取,从新leader能读取到新记录,旧leader只能读取到旧记录,从整个系统的角度看违背了线性一致性。
引申一下,通过设计超时时间来解决这样的问题,貌似是可行的。假设选举超时重选时间为electionTimeout,心跳失败放弃leadership的时间阈值为stepdownTimeout,如果electionTimeout»stepdownTimeout,只要时钟不会严重抖动,基本能保证新leader选出前旧leader已经自行了断了。不过这里的靠谱程度跟设计的超时多大是正相关的。
另外,raft并不限定在propose结果返回给调用方前必须提交到状态机,很可能会出现这样的情况:commitIndex包含了之前propose的记录,但状态机applyIndex还小于commitIndex,即还没来得及提交到状态机。为了保证先写后读的可见性问题,一旦写入时承诺了某个commitIndex,下次读取的时候需要等到applyIndex大于等于该Index(或者后续某个commitIndex,因为是单调递增的)才能返回,这样才能确保线性一致性。
下面介绍几种在raft实现线性一致性读的方法。
Read as Proposal
为了确保处理读请求时还保有leadership,那么可以在将读请求作为proposal直接走一次raft,当该entry能够提交到状态机执行读取时,leader可以将结果返回给调用方。
这样处理的逻辑是非常自然的,但开销也非常大,跟处理写请求时几乎一致。
ReadIndex
ReadIndex的处理方法省掉了额外的IO,leader在发起读时记录当前的commitIndex,然后在后续heartbeat请求中如果能获得多数派对leadership的确认,那么可以等待commitIndex提交到状态机后即可返回结果。
这里面可以做一些优化,以最近在看的dragonboat为例,有连续N个ReadIndex方式的读请求,那么leader可以为每一个这样的读请求分配一个唯一ID并保存收到请求时的commitIndex。由于commitIndex单调递增的特性,这里保存下来读请求对应的commitIndex至少是非递减的。每次发送heartbeat时顺带上最近一个ReadIndex的ID,如果heartbeat得到多数派确认,则该ID对应的ReadIndex请求也得到确认,那么该请求之前的ReadIndex也变相被确认。这个逻辑大概是在internal/raft/readindex.go。
- raft内部记录正在处理的ReadIndex请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25func (r *readIndex) addRequest(index uint64, ctx raftpb.SystemCtx, from uint64) { if _, ok := r.pending[ctx]; ok { return } // index is the committed value of the cluster, it should never move // backward, check it here if len(r.queue) > 0 { p, ok := r.pending[r.peepCtx()] if !ok { panic("inconsistent pending and queue") } if index < p.index { plog.Panicf("index moved backward in readIndex, %d:%d", index, p.index) } } r.queue = append(r.queue, ctx) r.pending[ctx] = &readStatus{ index: index, from: from, ctx: ctx, confirmed: make(map[uint64]struct{}), } } - 处理heartbeat回包时顺便判断哪些ReadIndex得到确认,确认后的请求通过ReadyToRead传到外面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40func (r *readIndex) confirm(ctx raftpb.SystemCtx, from uint64, quorum int) []*readStatus { p, ok := r.pending[ctx] if !ok { return nil } p.confirmed[from] = struct{}{} if len(p.confirmed)+1 < quorum { return nil } done := 0 cs := []*readStatus{} for _, pctx := range r.queue { done++ s, ok := r.pending[pctx] if !ok { panic("inconsistent pending and queue content") } cs = append(cs, s) if pctx == ctx { for _, v := range cs { if v.index > s.index { panic("v.index > s.index is unexpected") } // re-write the index for extra safety. // we don't know what we don't know. v.index = s.index } r.queue = r.queue[done:] for _, v := range cs { delete(r.pending, v.ctx) } if len(r.queue) != len(r.pending) { panic("inconsistent length") } return cs } } return nil }
Lease Read
在raft作者的博士论文里也提出了Lease Read的方法,作为ReadIndex的简化。Lead Read可以认为是ReadIndex的时间戳版本,leader发起heartbeat请求时记录一个start时间戳,获得多数派确认后则可以保证leadership的截止时间至少到start+election_timeout,那么在此之前的读请求都可以直接从状态机读。
相比前者,这里的逻辑负担会更少,不过完全依赖时间戳并非靠谱的方案,如前所述当时钟抖动时很可能会引发一些问题,除非超时阈值特殊设计一下。